AI Singapore · Platforms Engineering
Sovereign AI platform
for Apple Silicon.
Orchard lets you operate AI infrastructure. Serve, customize, and govern on your own hardware. OpenAI-compatible APIs, multi-tenant governance, and on-prem deployment.
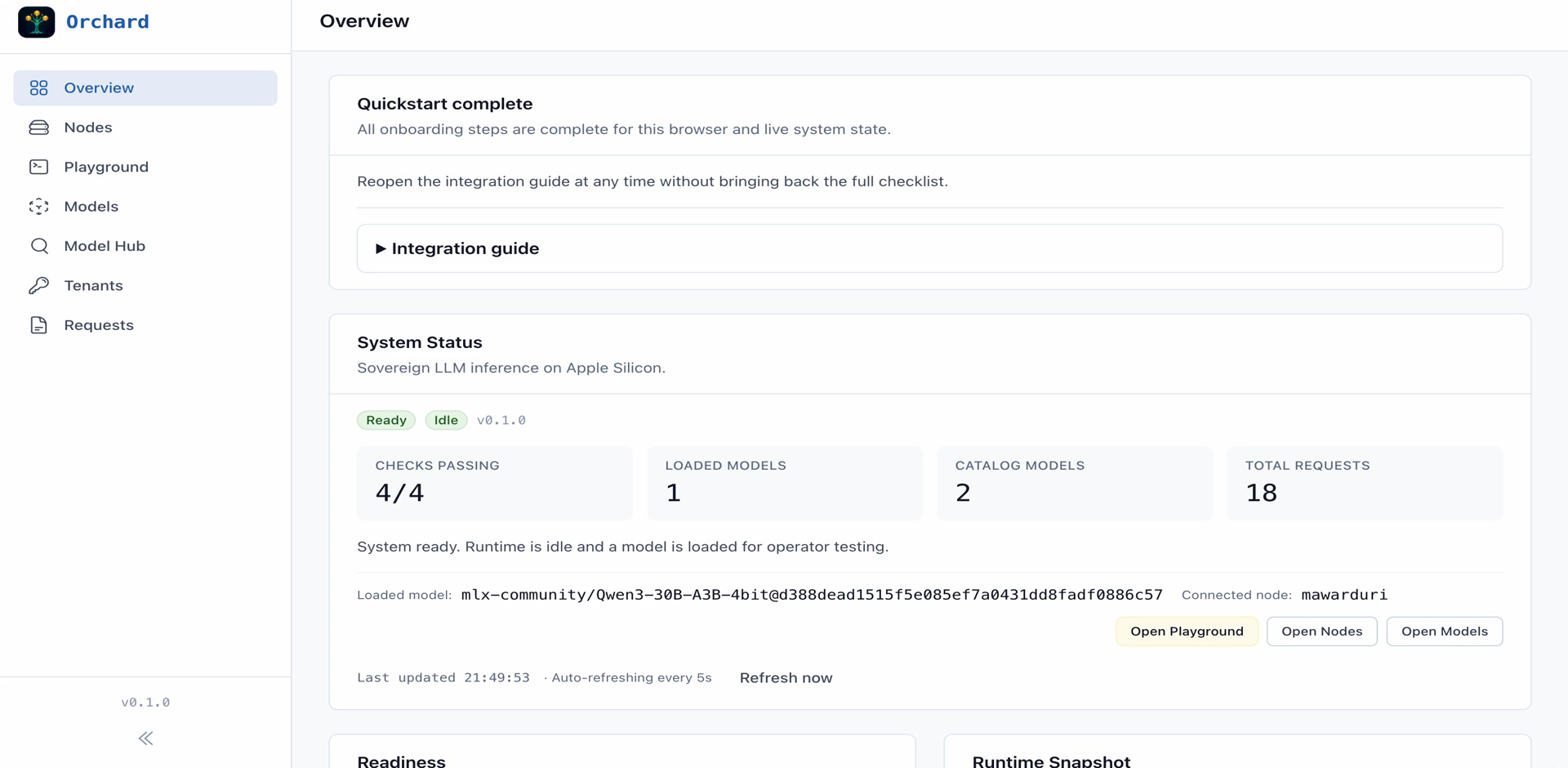
Orchard Console walkthrough — SEA-LION 27B streaming on Apple Silicon (M3 Max)
Orchard
A sovereign AI platform built from the ground up for Apple Silicon. Drop-in OpenAI API compatibility means your existing tools, SDKs, and workflows work without modification. Your hardware, your data, your API.
Used in-house at AI Singapore to serve AI inference for 100 Experiments, AIEH, and SIP programme teams.
Sovereign by Design
Data never leaves your infrastructure. Run inference on hardware you physically control, with full audit trails and governance built in from day one.
Multi-Tenant Governance
Tenants, API keys, RBAC, usage tracking, and rate limiting. Serve multiple teams from a single cluster with proper isolation and auditability.
Production-Ready
Built for concurrent streaming to many users at once. Simple DMG/PKG packaging. Real-time console for live monitoring and management.
Built by AI Singapore
Built for Our Teams. Available for Yours.
From AI Singapore's Platforms Engineering team. We're deploying Orchard to our AI engineering teams and selected industry partners through our 100 Experiments and SIP programmes.
- ✓ Deploying to AISG's Apple Silicon infrastructure
- ✓ Available for 100E and SIP industry projects
- ✓ Backed by seven years of platform engineering
How It Fits Together
Orchard sits between your applications and Apple Silicon hardware. One API, any client, full control.
- Python / TypeScript SDKs
- curl / REST
- Custom applications
e.g. Cherry Studio, Open WebUI, Cursor
- OpenAI-compatible API
- LiveView console
- Governance & audit
- Model management
- M2, M3 Max, M3 Ultra & beyond
- 24 GB – 512 GB unified memory
- MLX inference engine
- macOS launchd services
Mac Mini · Mac Studio · Mac Pro
All traffic stays on your network. No cloud dependency.
How It Works
Orchard runs natively on macOS. Install via Homebrew, start the service, and you have a governed inference endpoint on your local network. No containers. No cloud dependency.
Deployment
- 1 macOS packaging
DMG/PKG installer with launchd service management. Controller is platform-agnostic. No Docker required.
- 2 One-command setup
Install, configure, and start serving in minutes. No containers, no cloud dependency.
- 3 LAN-ready
HTTPS transport for secure access across your local network. Serve teams from a single cluster.
Live today
- ✓ Single-node production inference on Apple Silicon
- ✓ LiveView console with streaming playground and real-time metrics
- ✓
OpenAI-compatible API (
/v1/chat/completions+ SSE) - ✓ Multi-tenant API keys and governance
- ✓ Third-party client support (Cherry Studio, SDKs, custom apps)
In progress
- ◦ Multi-node clusters (up to 20 Mac Studios)
- ◦ RBAC and usage-based quotas
- ◦ HTTPS/LAN transport with managed TLS
Built For
Orchard fits anywhere you need governed LLM inference without a public cloud dependency.
Internal AI Labs
Stand up a governed inference platform for your engineering and business teams. OpenAI-compatible APIs mean existing tools work on day one.
Sovereign Inference
Keep data on infrastructure you physically control. No data leaves your premises. Full audit trails for compliance and governance requirements.
Apple Silicon Clusters
Purpose-built for Mac Studio and Mac Pro hardware. Leverage unified memory architecture for efficient inference on models up to 70B parameters.
SME Deployments
Right-sized AI infrastructure for small and medium enterprises. No GPU server room required — a Mac Studio cluster fits on a desk.
The Team Behind Orchard
Orchard is built by the Platforms Engineering team at AI Singapore, the national AI programme. We build and operate the governed AI infrastructure that engineering teams depend on — multi-tenant, cycle-tested, and production-hardened across seven years of 100E, AIEH, SIP, and AIAP delivery.
On-prem, network, servers, security
Cloud, IT accounts, data platform
Model serving, pipelines, tooling
Product engineering, UX, apps
Have an AI challenge?
Tell us what you're working on. We'll explore how Orchard and our AI programmes can help.